
batchLLM
Because the identify implies, batchLLM is designed to run prompts over a number of targets. Extra particularly, you possibly can run a immediate over a column in a knowledge body and get a knowledge body in return with a brand new column of responses. This could be a helpful method of incorporating LLMs in an R workflow for duties reminiscent of sentiment evaluation, classification, and labeling or tagging.
It additionally logs batches and metadata, allows you to evaluate outcomes from completely different LLMs aspect by aspect, and has built-in delays for API charge limiting.
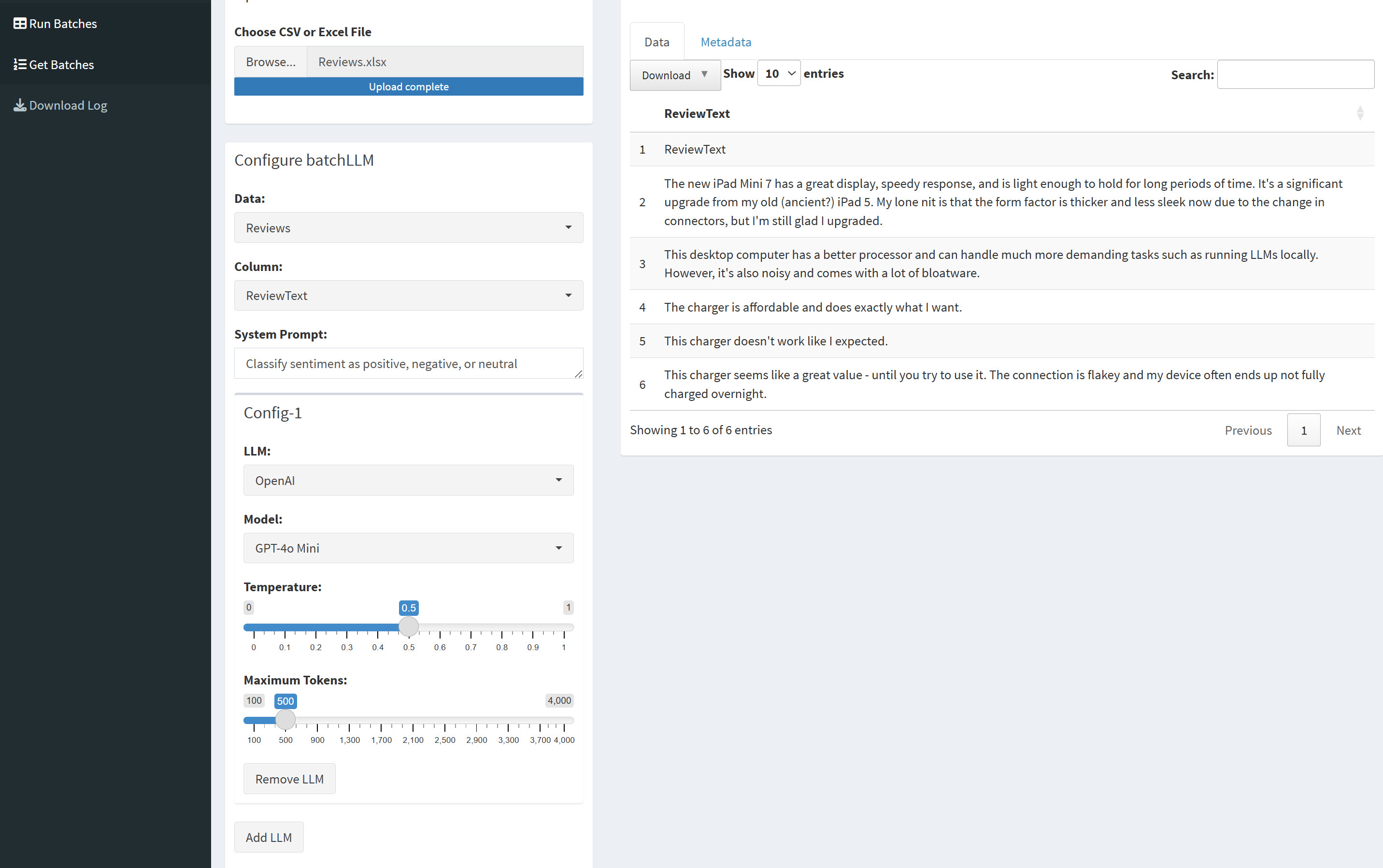
batchLLM’s Shiny app provides a helpful graphical consumer interface for working LLM queries and instructions on a column of information.
batchLLM additionally features a built-in Shiny app that offers you a helpful internet interface for doing all this work. You’ll be able to launch the net app with batchLLM_shiny() or as an RStudio add-in, when you use RStudio. There’s additionally a web demo of the app.
batchLLM’s creator, Dylan Pieper, mentioned he created the bundle because of the must categorize “hundreds of distinctive offense descriptions in court docket knowledge.” Nevertheless, be aware that this “batch processing” software doesn’t use the cheaper, time-delayed LLM calls supplied by some mannequin suppliers. Pieper defined on GitHub that “a lot of the providers didn’t provide it or the API packages didn’t help it” on the time he wrote batchLLM. He additionally famous that he had most well-liked real-time responses to asynchronous ones.
We’ve checked out three prime instruments for integrating massive language fashions into R scripts and packages. Now let’s take a look at a pair extra instruments that target particular duties when utilizing LLMs inside R: retrieving info from massive quantities of information, and scripting widespread prompting duties.
ragnar (RAG for R)
RAG, or retrieval augmented generation, is among the most helpful purposes for LLMs. As a substitute of counting on an LLM’s inside information or directing it to look the net, the LLM generates its response based mostly solely on particular info you’ve given it. InfoWorld’s Smart Answers characteristic is an instance of a RAG software, answering tech questions based mostly solely on articles printed by InfoWorld and its sister websites.
A RAG course of usually entails splitting paperwork into chunks, utilizing fashions to generate embeddings for every chunk, embedding a consumer’s question, after which discovering probably the most related textual content chunks for that question based mostly on calculating which chunks’ embeddings are closest to the question’s. The related textual content chunks are then despatched to an LLM together with the unique query, and the mannequin solutions based mostly on that supplied context. This makes it sensible to reply questions utilizing many paperwork as potential sources with out having to stuff all of the content material of these paperwork into the question.
There are quite a few RAG packages and instruments for Python and JavaScript, however not many in R past producing embeddings. Nevertheless, the ragnar package, at present very a lot beneath improvement, goals to supply “an entire answer with wise defaults, whereas nonetheless giving the educated consumer exact management over all of the steps.”
These steps both do or will embody doc processing, chunking, embedding, storage (defaulting to DuckDB), retrieval (based mostly on each embedding similarity search and textual content search), a method known as re-ranking to enhance search outcomes, and immediate era.
If you happen to’re an R consumer and interested by RAG, keep watch over ragnar.
tidyprompt
Severe LLM customers will seemingly need to code sure duties greater than as soon as. Examples embody producing structured output, calling capabilities, or forcing the LLM to reply in a selected method (reminiscent of chain-of-thought).
The concept behind the tidyprompt package is to supply “constructing blocks” to assemble prompts and deal with LLM output, after which chain these blocks collectively utilizing standard R pipes.
tidyprompt “must be seen as a software which can be utilized to reinforce the performance of LLMs past what APIs natively provide,” in keeping with the bundle documentation, with capabilities reminiscent of answer_as_json(), answer_as_text(), and answer_using_tools().
A immediate will be so simple as
library(tidyprompt)
"Is London the capital of France?" |>
answer_as_boolean() |>
send_prompt(llm_provider_groq(parameters = checklist(mannequin = "llama3-70b-8192") ))
which on this case returns FALSE. (Notice that I had first saved my Groq API key in an R surroundings variable, as could be the case for any cloud LLM supplier.) For a extra detailed instance, take a look at the Sentiment analysis in R with a LLM and ‘tidyprompt’ vignette on GitHub.
There are additionally extra advanced pipelines utilizing capabilities reminiscent of llm_feedback() to test if an LLM response meets sure situations and user_verify() to make it potential for a human to test an LLM response.
You’ll be able to create your personal tidyprompt immediate wraps with the prompt_wrap() operate.
The tidyprompt bundle helps OpenAI, Google Gemini, Ollama, Groq, Grok, XAI, and OpenRouter (not Anthropic instantly, however Claude fashions can be found on OpenRouter). It was created by Luka Koning and Tjark Van de Merwe.
The underside line
The generative AI ecosystem for R is not as robust as Python’s, and that’s unlikely to alter. Nevertheless, prior to now 12 months, there’s been lots of progress in creating instruments for key duties programmers may need to do with LLMs in R. If R is your language of alternative and also you’re interested by working with massive language fashions both domestically or through APIs, it’s value giving a few of these choices a attempt.